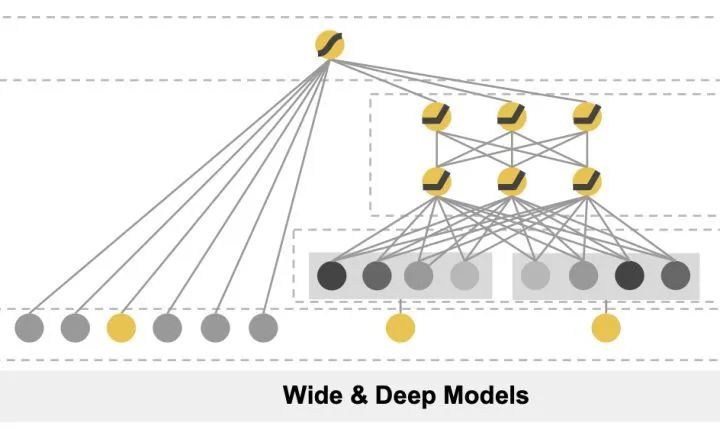
Wide&Deep模型
- 提出年份:2016年
- 提出者: 谷歌
- 结构:
- Wide: 单层网络,作用是让模型具有较强的记忆能力(学习并利用特征在历史数据中的的“共现关系”的能力,可理解为"吃一堑,长一智"的能力 )
- Deep: 多层网络,作用是让模型具有泛化能力 ( 可理解为“触类旁通”的能力:模型学习样本特征参数,并保证参数可用于具有低频稀疏组合特征的样本的能力 )
- 缺点: 人工构造交叉特征,需要对特征有充分的理解,耗时耗力,且容易有遗漏
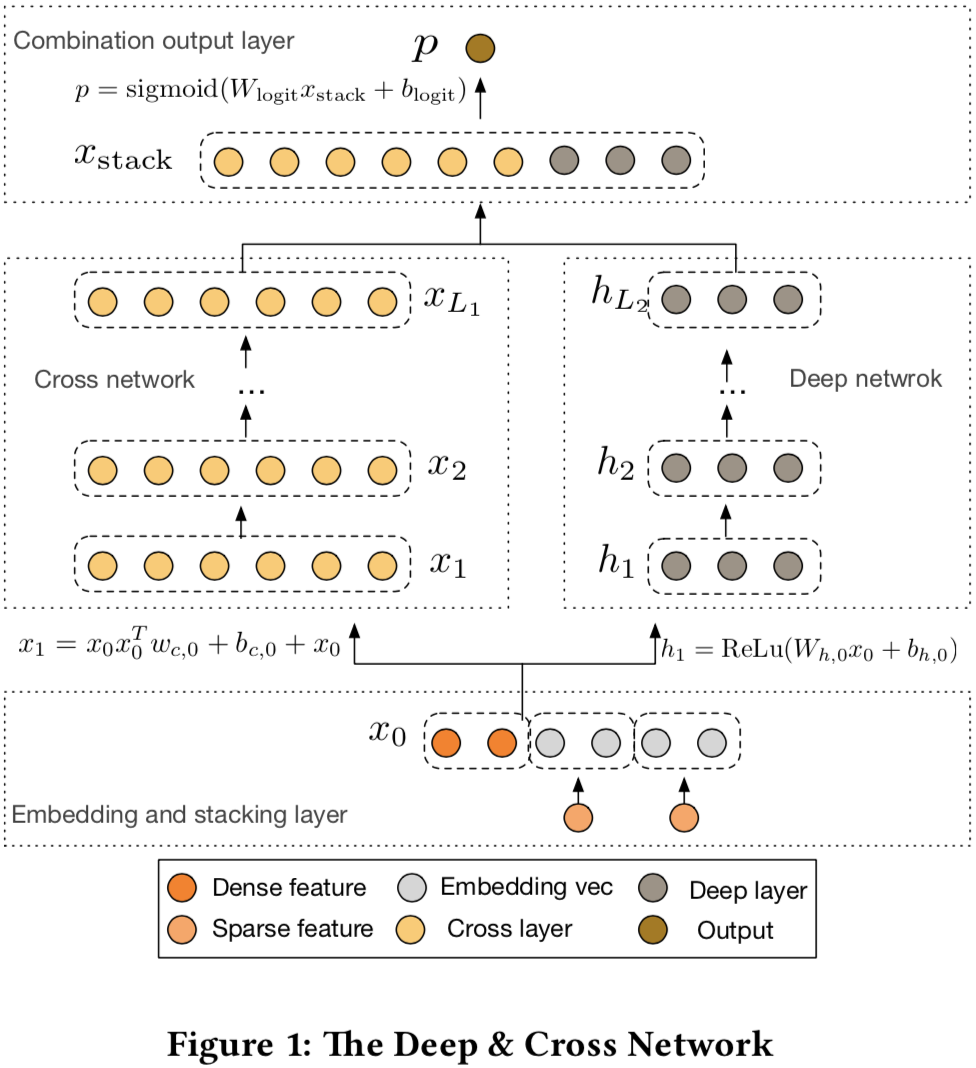
Deep&Cross
- 提出年份:2017
- 提出者:斯坦福和谷歌研究者
- 是Wide&Deep的一个变形, 将Wide部分替换成了Cross
- Wide各层迭代公式:

(1)
- 特征处理:
- sparse特征: embedding
- multi-hot的sparse特征: embedding后做average pooling
- dense特征: 做归一化
- 上述embedding和dense特征拼接后, 作为Cross和Deep共同的输入:

(2)
Cross
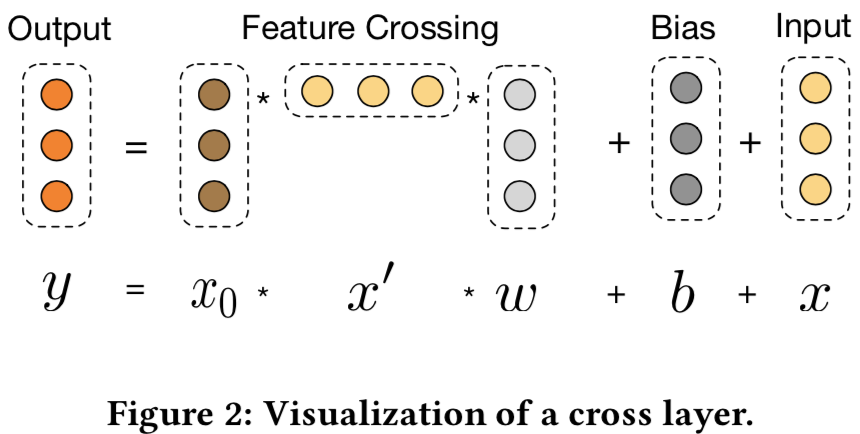
- 结构设计机理
- 以2层cross网络为例, 设x0=(x01, x02)T, 令bi=0, 则

(3)
- x2的公式为

(4)
- x1包含了x01, x02从一阶到三阶的所有可能的交叉组合
- 有限高阶: 深度Lc对应最高Lc+1阶交叉
- 自动叉乘: 最后一层包含输入特征从一阶到Lc+1阶所有叉乘组合,而模型参数量分别随输入维度d和Lc线性增长:2dLc
- 参数共享: 不同叉乘组合存在参数共享,降低了参数量,增强了泛化能力和鲁棒性。例如,如果独立训练权重,当训练集中某叉乘特征没有出现 ,对应权重为零,而参数共享则不会
- Cross的优点:
- 各层神经元的个数相同,都等于x0的维度d
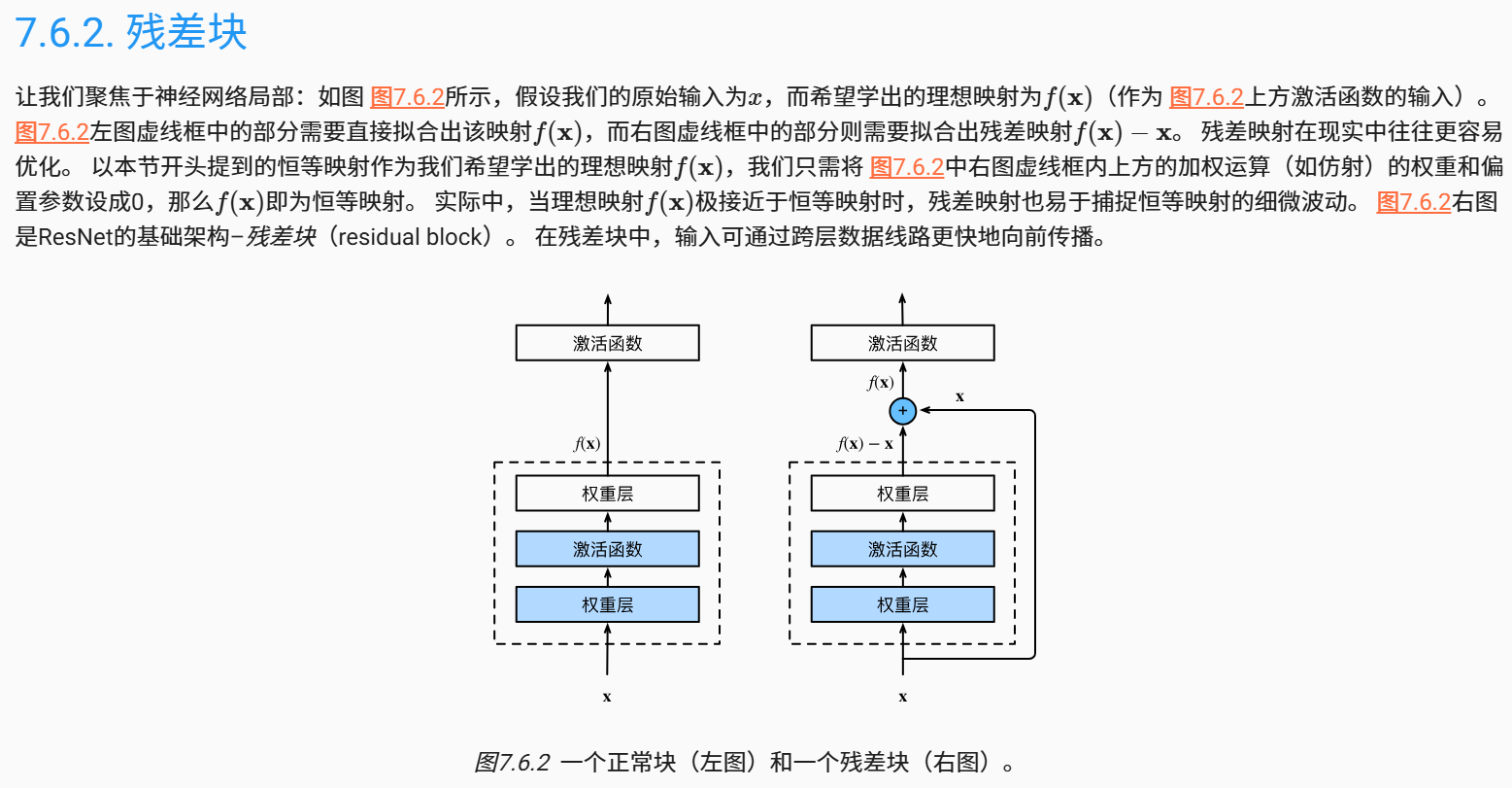
- 公式(1)的作用和残差网络(Residual Network)相似,用于拟合xl+1-xl
, 防止梯度消失,使网络可以更深
- DCN自动学习高阶的特征组合
- 告别了繁琐的人工叉乘
残差网络